Introduction
In Goldin and Rouse, 2000, they claim to find that the introduction of blind auditions for orchestras had a large impact on the hiring of women.
I previously wrote a post about this study, describing that it does not present any good evidence for the claims. This post has received a lot of attention, and the discussion of it has lead to some new perspectives. Rather than changing that original post, I will write an updated version here.
The surprising thing about this, is that even though the study does not contain any good evidence for their hypothesis, it is extremely well-known and often used as an example of scientifically proven gender discrimination. Here is a quote from The Guardian in one of the frequently cited newspaper articles about it:
Even when the screen is only used for the preliminary round, it has a powerful impact; researchers have determined that this step alone makes it 50% more likely that a woman will advance to the finals. And the screen has also been demonstrated to be the source of a surge in the number of women being offered positions.
Even just since I wrote the blog post in February, the study has been mentioned and written about numerous times. For instance here, here, here, here, here, and so on. A search for the newest mentions of “blind auditions orchestras” on Twitter currently gives me these results:
In the discussion I have seen of my blog post, my critical view of the study has been generally accepted, including in a blog post by Gelman. Below I give an updated version of this critique.
Analysis
Table 4 is perhaps the most surprising.
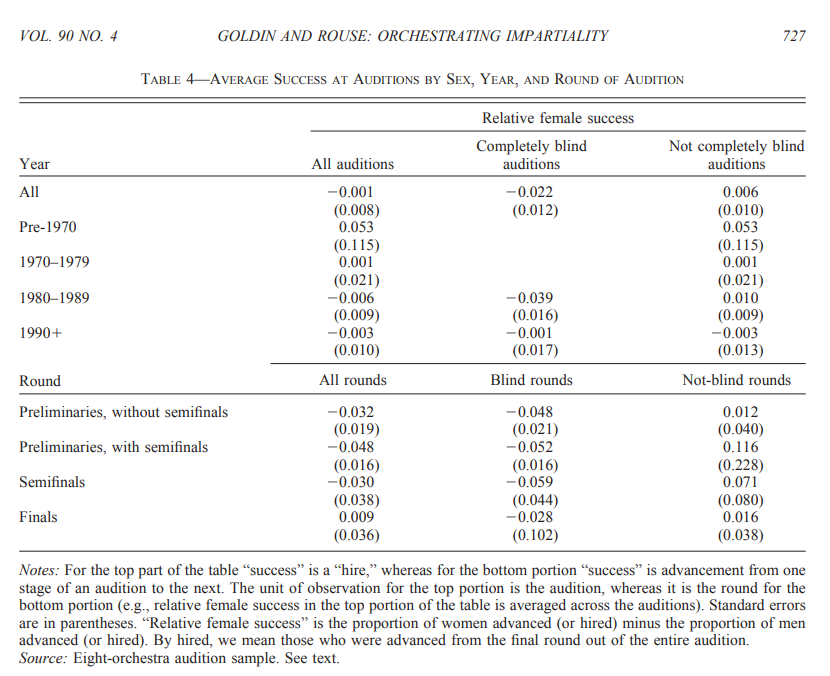
This table unambiguously shows that men are doing comparatively better in blind auditions than in non-blind auditions. The -0.022 number is the proportion of women that are successful in the audition process minus the proportion of men that are successful. Thus a larger proportion of men than women are successful in blind auditions, the exact opposite of what is claimed.
However, as I describe in my original post, this is observational data, and could be confounded in many ways. Thus I would not rely on it to draw any conclusions. But it is noticeable that the most significant result in the paper is in the opposite direction of the overall conclusion drawn.
In table 5 the authors attempt to address the confounding issues by looking at data where the same people have applied to both orchestras that use blind auditions and orchestras that use non-blind auditions.
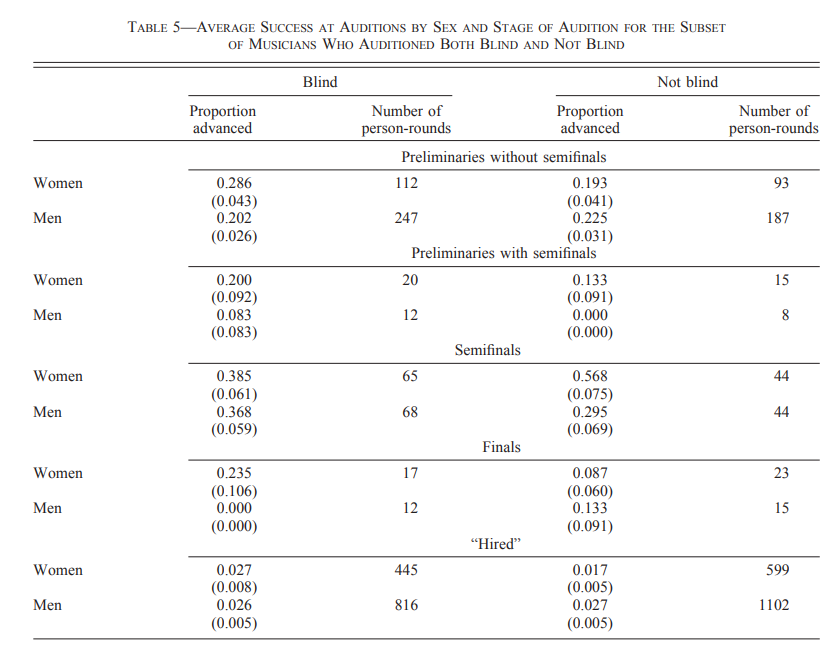
I don’t think this data is of sufficient size and nature to draw any conclusions from, for the following reasons:
While women have a higher proportion advanced in several categories, they have a lower proportion advanced in the semifinals category.
The numbers have very large standard errors, and the difference in proportions is not statistically significant for any of the groups.
Even if the results did show a clearly increased proportion of women advanced in blind auditions, this data is from very few orchestras (1-3 depending on the category).
Another attempt to deal with the confounding issue, is to perform a regression analysis with controls:
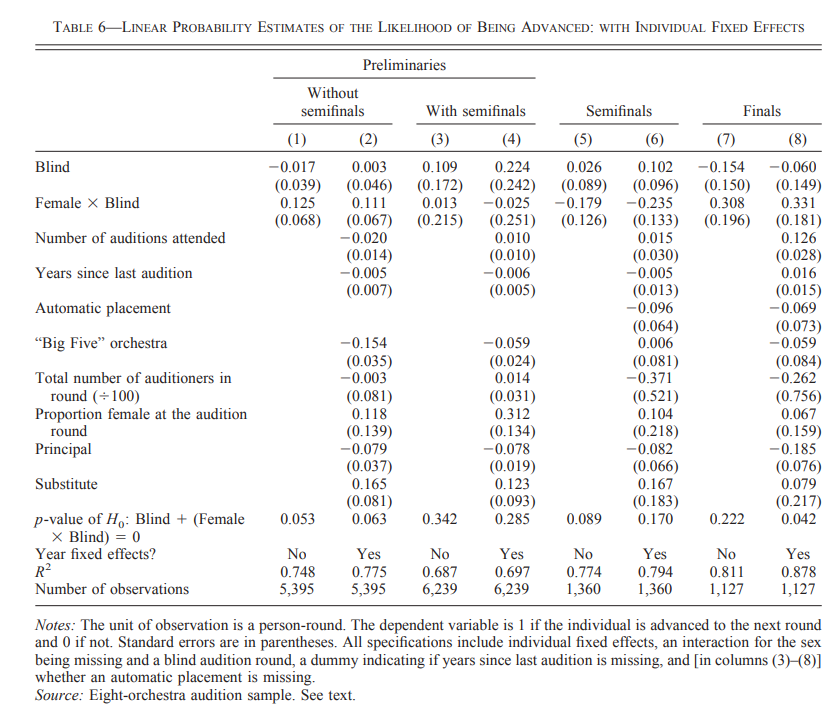
This analysis has many of the same problems as the previous one: The values fluctuate wildly, the standard errors are large, the proportion of men advanced in blinded auditions in the semifinals is higher, not lower, and the p-values are not significant. (There is one marginally significant p-value in the table, but it should be adjusted for multiple testing, which gives us a p-value of 0.33).
I think that you should generally view non-preregistered results from complicated regression models with some skepticism, since it gives a large researcher degree of freedom. However, in this case it is not necessary to think in those terms, since there is no significant result in the table anyway.
They also present some other analyses in the paper, for which the authors admit that “standard errors are large and thus the effect is not statistically significant.”
Discussion
So how did we get to this situation, where for 19 years this study was accepted by everyone, as giving the final word on the impact of blind auditions on gender discrimination?
The conclusion mentions some considerations about statistical significance. However, it also makes this statement:
Using the audition data, we find that the screen increases—by 50 percent—the probability that a woman will be advanced from certain preliminary rounds and increases by severalfold the likelihood that a woman will be selected in the final round. By the use of the roster data, the switch to blind auditions can explain 30 percent of the increase in the proportion female among new hires and possibly 25 percent of the increase in the percentage female in the orchestras from 1970 to 1996.
These numbers are used in news articles most of the time without caveats, as illustrated in the Guardian quote above. But this absolutely should not be done. All these estimates are extremely noisy, with high standard errors, and the confidence intervals include a large section of both positive and negative values.
Unfortunately, it is not clear what else the journalists could be expected to do in this case. After all, they just quoted directly from some values in a published, peer reviewed study. Even if you can demand some statistical insight from science journalists, expecting them to independently verify results is too much.
In my opinion, this illustrates a huge problem regarding the communication between researchers and journalists, that likely affects an enormous amount of science journalism. I think the science world should make better efforts to help science journalists more accurately convey statistically complicated study results.